
今回は初のプログラミングについてです。
色々書きたいことはありますが、まずは作成したものを紹介します。
# おまじない
import time
from selenium import webdriver
# ①ブラウザ(Chrome)を開く
driver = webdriver.Chrome()
# ②指定したサイトを開く
driver.get(‘https://www.buffett-code.com/’);
time.sleep(3)
search_box = driver.find_element_by_id(‘ac-search__top’)
search_box.send_keys(‘xxxx’)
search_box.submit()
time.sleep(5)
# 財務状況を取得する
stockprice_box = driver.find_element_by_id(‘stockprice’)
print(‘株価:’+stockprice_box.text)
financial_link = driver.find_element_by_link_text(‘業績’)
financial_link.click()
今日はここまで。
・・・実はまだ途中なんです。
やりたいことは、良さそうな銘柄の財務状況を調べて
「これは割安!」と思えるものをピックアップするようなのを作ろうとしています。
プログラムでやろうとしていることは、プログラム中に書いていますが、
① ブラウザ(Chrome)を開く
② 指定したサイトを開く
③ 財務状況を取得する
④ 取得情報を出力する
⑤ 取得した情報から欲しいデータを試算する
です。
「まだ途中」と言ったのは、③の途中で今日時点では終了しました。
今日はここまでの備忘録にしようと思っています。
①はそこまで難しいことじゃない・・・と思いきや
Seleniumとchromedriverのインポートで結構苦労しました(-_-;)
ググってみると環境変数が云々と書いているんですが、
Jupyter Notebookで先に「!pop install xxx」を実行する必要がありました。
chromedriverはブラウザのバージョンに近いものを探してインポートしておく必要があります。
②はサイトを開くことまでは簡単でしたが、
何故か銘柄コードを入れるところでエラーが出て解決できず、
ここでも小一時間・・・
「driver.find_element_by_id」のところを
最初は「driver.find_element_by_name」としていたのですが、
それではうまくできませんでした。間違っていないはずですが、
エラーが解決できなかった理由はわからず、結果オーライで進んでいます。
③は複数のページに跨って情報があるため、
ページの移動が必要でした。今はテーブル内のデータを入手する方法を探し中です。
以上までの実行結果が以下の通りです。

実行中はchromeが頑張って動いていました。
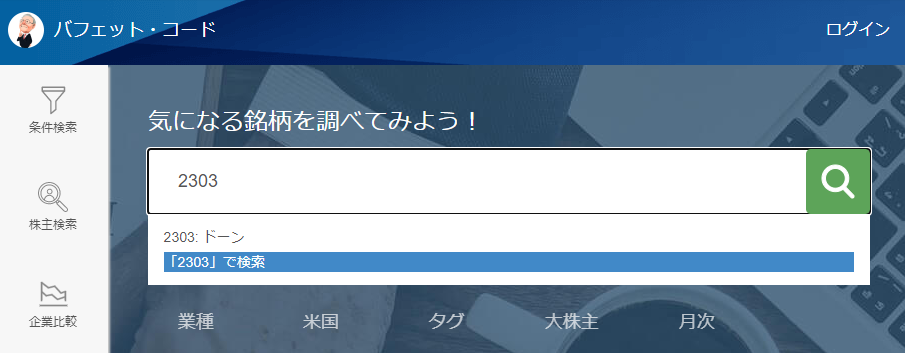
「バフェット・コード」を開いて、「気になる銘柄を調べてみよう!」に「2303」と入力。
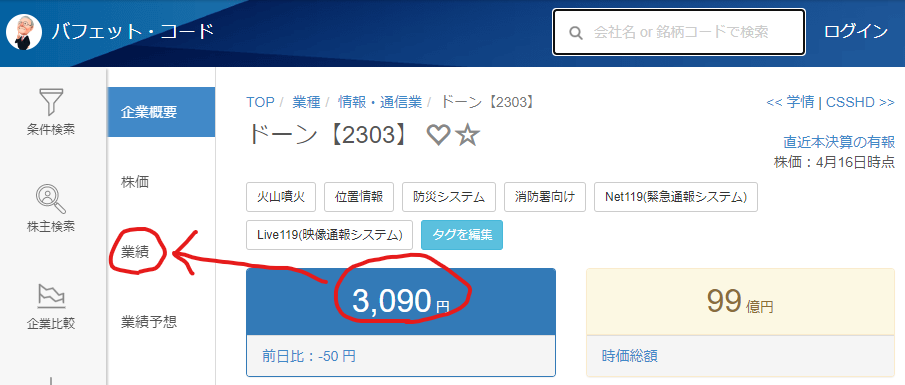
現在の株価「3,090円」を取得して、業績のページに移動
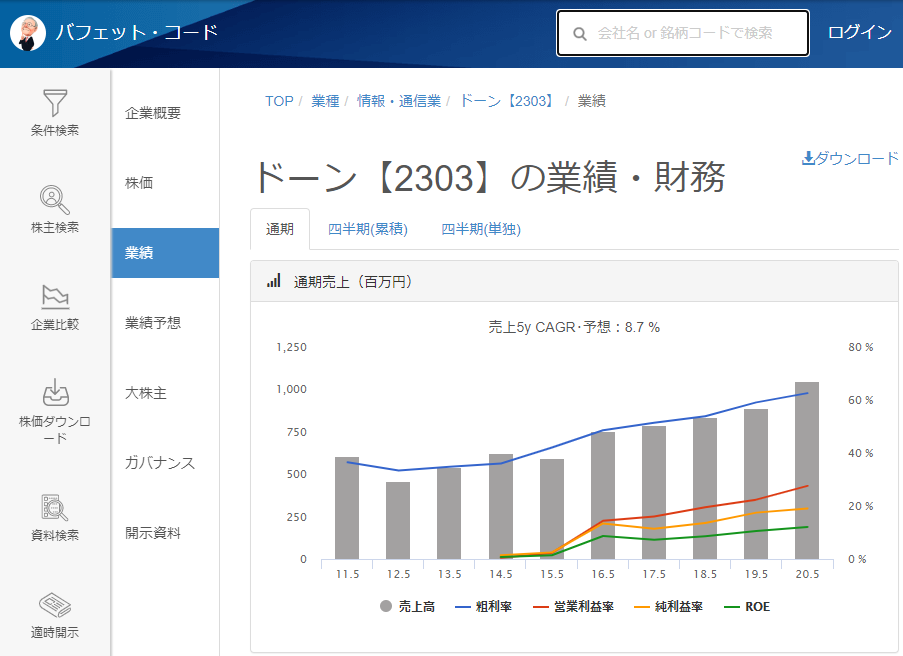
業績ページを開いて、一旦終了です。
GW中にある程度形にしたいなと思います。


コメント